At this point I’m not sure whether to call this weekly any more cause I’m just haphazardly writing roughly on a weekly basis but damn it I’m just going to keep this going.
I am pleased to say that I have finally passed my AWS DevOps Engineer – Professional certification! It was quite a lot of hard work, like it was honestly harder than I expected it to be cause most of the questions were situational and very AWS specific in-terms of CICD. Honestly, I took this because I thought it would be easier compared to the Solution Architect Professional. But man I was wrong.
This also means that I would probably be looking to pick up the CSAP cert when I have the time for it, perhaps at the end of the year.
It has been a long time since I’ve studied so hard for something, and it was really helpful not just for the exam, but I realized that there were a lot of tools/services I could’ve used for my current team that we weren’t using yet. I think we are very capable in designing functional services, but there’s still a gap between change management and having full visibility over everything. I’m planning to apply some of the things I’ve learnt in my team, cause it helps to bring us one step closer to having DevOps as culture.
In preparation for my upcoming AWS Exams, I’ve gotten some PDF materials to go through and study. However, the formatting of the document is terrible, and it made it really hard for me to study.
So I moved to my iPad, hoping that some Apple magic might help with making the text more readable instead of sprawling across the entire width of the screen. That didn’t help.
“There has got to be a way to reflow the text”, I thought. I ended up downloading 3 different PDF reader apps looking for that magical bullet that would solve all my problems.
One didn’t have the functionality
One worked but it made the format worse
One works beautifully, but I cannot annotate or highlight in the “Reflow” mode which made it basically useless for studying
I gave up on the iPad and I thought, there has to be a way on the Desktop that would help me to reflow the text. My default go-to PDF reader: SumatraPDF didn’t have that option. After Googling for way too many minutes, there was basically no obvious option that could solve my problem of having reflowable text and still annotatable (and free).
It was when I came across (rediscovered) that yes, you could convert a PDF into a Word document. So I quickly searched for “Word” in my start menu and guess what, I don’t have it; because I recently formatted my computer. The version I had in the past was my education version that I shouldn’t have access to anymore. But I still tried, logging into my old school email to dig for that option that allows me to install Office.
You currently do not have a valid Office subscription for your account
Web Microsoft Outlook circa Sep 2020
That led me to searching online for what’s the cheapest way to get Office legitimately, preferably something that is a one-time license and not a subscription fee for a product that I only use infrequently. It was during this search that I saw someone mention that “education” should be free. I thought, okay, why not give it another shot.
Bam! Logging in with my student email through the official Microsoft Office site gave me an option to download a genuine version of Office that is properly licensed. The best part? I apparently performed some kind of voodoo in the past for claiming office, and the license actually belongs to my personal account and it all ties in nicely with my existing documents.
I finally have Word now.
Yes, it was able to convert PDFs into a Word document, no problem. This solves my reflow and annotation problems.
Then I thought, hey, doesn’t this mean that I could now study on my iPad?
Pushed the document over to my iPad then I thought, “wouldn’t it be nice to have Word here too”. I remembered that I was able to use it freely on my 8″ Xiaomi Tablet. Downloaded it, fired it up and it asked for my account, I logged in, only for it to tell me that
You currently do not have a valid Office subscription for your account
IOS Microsoft Word circa Sep 2020
Confused, I did a quick check online, so…
Apparently, any devices >10 inches are considered professional use, which basically rules out all iPad Pros out there. Which means that I would need to purchase a subscription in order to use it. Nevertheless, this caused me to open the Pages app for the first time ever, and it managed to open up the document flawlessly.
It was at this point when my girlfriend asked me, “why not just print this out?”
….
In my relentless pursue for a digital solution to read a damn PDF comfortably, it totally slipped my mind that sometimes having a physical copy is much simpler and elegant.
Took an online introductory course (Udemy) on Microsoft Azure AZ-900 because lo-and-behold, my team has chosen the Azure platform for our translation services (will write more about this next time).
As someone who has been 99.99% working on the AWS platform and Linux systems in general, Azure feels pretty foreign because most of the concepts seem to tie into the Windows systems more so than anything else.
Access control? Active Directory
RBAC? Active Directory
Networking? Virtual networks
Pricing? Subscriptions
Compliance? Almost everything under the roof
The main difference I find between AWS and Azure is that: AWS is a loose collection of services that are “grouped” through networking, Azure is a logical collection of services that are “grouped” by “folders” of resources.
The title sounds grander than this really is. It was one of those work days where I felt like I didn’t get much done. I checked my calendar and there wasn’t many meetings, only the one in the morning. It felt like a really busy day but I couldn’t think of a concrete task that I have accomplished that day.
As I lay in my bed, tossing and turning, being unable to sleep, I figured out why I couldn’t get my tasks done for the day, and came up with a simple workflow that would solve this.
Why I wasn’t able to work on my tasks
A day in the life of a software/devops engineer is pretty chaotic. You have various information requiring different context streaming in from multiple sources throughout the day. For example, I was working on updating some configuration mapping on Kubernetes for our new SES SMTP Relay credentials. Then I get a message clarifying about a story that I completed yesterday, about a backend API written in GO. Then I had to join a meeting about decoupling our entire platform from an external service that many of our logic is intertwined with.
This came about because of something I discovered recently about building a second brain. The prospect of it is extremely enticing for me.
Idea is that over time you build a second brain that is like a digital collection of all the knowledge that you’ve gained over your lifetime.
As someone working in the digital field, the amount of information that I go through on a daily basis is pretty huge. I’ve been taking notes for a million and one things, but I realize that I’ve almost never really gone through my notes and make something out of it. Which I felt has been really wasteful because, why would I even write them in the first place if I’m not going to use it? How many % of the things I’ve written can I actually remember in my dumb human brain?
Armed with the motivation to build a digital brain that I can tap into for creating new ideas and products, I embarked on part 1 of the journey.
Finding the right tool
The “original” tool (that I know of) is known as Roam Research, however, it’s a web only tool currently, and it’s a paid service of $15/month. This makes it slightly undesirable as I would prefer if it’s something that I could potentially migrate/export out of the system. I also wish that there exist a free option that I can try out to see if this second brain business is something that I really want.
I checked out 8 different not taking tools to see what works for me and compare across them.
The past week has been extremely exciting and nerve-wrecking. My team has finally completed the migration from on-premise to the cloud. It’s the first time that I’ve done anything like this and I’m blessed to have someone senior to lead us through the migration period.
ps: I wrote but forgot to post so this was actually 2-3 weeks ago
I’m a part of the MyCareersFutureSG team, so our users are the working population of Singapore, and we host hundreds of thousands of job postings, so there are definitely some challenge in migrating the data.
It’s the first time that I’ve handled such huge amounts of data when migrating across platform and the validation and verification process is really scary, especially when we couldn’t get the two checksum to match. It’s also the first time that I’ve done multiple Kubernetes cluster base image upgrade rollover. There were multiple occasions where we were scared that the cluster will completely crash but it managed to survive the transition.
Let me sum up the things I’ve learnt over the migration.
When faced with large amount of data, divide and conquer. Split data into smaller subsets so that you have enough resource to compute.
When rolling nodes, having two separate auto scaling groups will allow you to test the new image before rolling every single node.
If you want to tweak the ASG itself, detach all the nodes first so that you will have an “unmanaged” cluster, then no matter what you do to the existing ASG, at least your cluster will still stay up.
When your database tells you that the checksum doesn’t match, make sure that when you dump the data, it’s in the right collation, or right encoding format
Point your error pages at a static provider like S3, because if you point it at some live resource, there’s a chance that a mis-configuration will show an ugly 503 message. (something that happened briefly for us)
Data less than 100GB is somewhat reasonable to migrate over the internet these days
Running checksum hash on thousands and thousands files is quite computationally and memory intensive, provision enough resources for it.
Overall, the migration actually went over quite well and we completed ahead of time. Of course, the testing afterwards is where we find bugs that we have never found before because it’s the first time in years that so many eyes are on the system at the same time.
The smoothness is also thanks to the team who has carefully planned the steps required to migrate the data over, as well as setup streaming backups to the new infrastructure so that half of the data is already in place and we just need to verify that the streamed data is bit perfect.
Since it’s been a couple of weeks since this happened, I realize that I am lucky to be blessed with the opportunity to do something like this. Cause I’ve just caught up with my friends and most of the times, their job scopes don’t really allow them to do something that far out of scope. Which… depending on your stage of life it could be viewed as a pro/con. I’m definitely viewing this 4 day migration effort over a public holiday weekend as positive cause it’s something not everyone can experience so early on in their career!
I think I missed out two weeks of entry because well… more discipline is needed when writing. However, it has been a really good two weeks because a lot of my purchases has come. One of the most notable one is the Drop CTRL Keyboard. a TKL keyboard that I’ve had my eyes on ever since it launched but couldn’t justify the purchase back then.
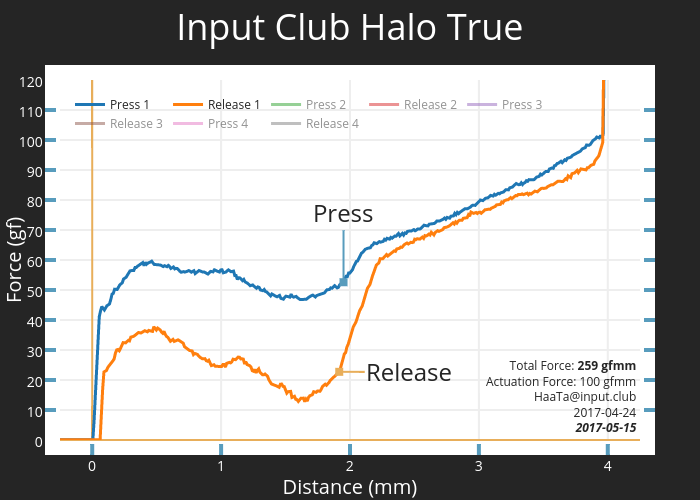
The version I got had a black aluminium case, with Halo True switches. This is my first experience with a more “premium” switch that isn’t Cherry MX or Gateron. It is also much heavier than I’m used to at 60g actuation force.
It felt way heavier than I’d liked at the start, but I’ve gotten used to it over the couple of weeks using it, and I’ve really gotten to liking how it feels. The tactile bump is much more pronounced than anything that I’ve tried before, and the very high force required for me to bottom out means that I rarely bottom out they keys which results in a quieter typing experience overall.
I’ve disassembled the keyboard, and lubed every single one of the switches with Krytox 205g0, also clipped, lubed and bandaid moded the stabilizers. All in all, it feels amazing and I never want to go back to using a keyboard that isn’t lubed like this anymore. The unfortunate part was that when I was lubing the stabilizers, I couldn’t get my hands on some thicker grease which would help with the dampening a little more. That has been rectified since.
I’m starting to build up my mechanical keyboard collection as I dive more into this hobby.
Krytox 205g0
Krytox 105
Superlube dielectric grease (PTFE)
20 x Durock T1 switches
10 x Durock Koala switches
Switch opener
Stem picker (4 prong)
Also bought two custom keycaps sets waiting for them to ship in a couple of months.
I’m extremely excited for GMK Mito Laster keycaps but I think it would only arrive next year, gotta keep my expectations in check.
All of these has made me realize that I really enjoy this hobby and I think I will consider getting more premium cases and boards next year. I am extremely curious about how it feels to use a keyboard with brass plate or carbon fiber plate.
Well, skipping the things that I had to do, one of the fun things that I’ve been exploring is Google Analytics. I’ve heard so much about it, and we actually used it in my current team (just that I haven’t really worked on this portion yet).
Went through the GA For Beginners course and it actually gives me a nice little certificate of completion. So that’s nice. I’m bringing this up because I want to experiment with it, which means that I’ve integrated it with this blog, as well as my landing page. Hopefully I can get some kind of metric at the end of the month. Unless the visitors of my sites are all bots, which would be a little disheartening.
Been busy with work and life that did not have the time to explore new things. Or maybe I did just that I forgot. Either way, the plan for the weekends is to explore Caddy as an automated way for me to deploy my portfolio/landing page, either that or cheating and using Netlify instead. The current flow I’m using relies on Ansible to deploy the page, which is a little bit manual in a sense. Hoping to change that.
We started doing benchmarking on our DB because one of our search queries has been slowing down significantly lately, and it’s affecting our user experience. In order to optimize the performance, we need a way of measuring the changes that we were going to implement.
What’s a centralized CI? It’s basically a template repository for CI pipelines. In this case, it’s for Gitlab because I’m familiar with it and it’s what I’m working with day in day out.
This idea started with my previous project team, but is slowly maturing as I figure out the various cases that it might be used/useful and tweak it accordingly. What it has currently is more of a MVP and POC that it can be used across various projects on Gitlab. You know that because the versioning currently only support patch and not minor/major bumps. It has something to do with how my current team does versioning but it’s the top of my list for things to improve.
Currently there are 4 repositories relying on the CCI, 2 of which are external but still within my control. Features will be incrementally added onto it, and I hope that this could really be something that would help people reduce the amount of time/complexity to build pipelines.