
Over the past couple of months I’ve been working on and reading up extensively on microservices. Numerous medium articles, and 2 books* later, here’s just a quick summary of the important points that I’ve learnt.
*Building Microservices – Sam Newman / Microservice Architecture – O’reilly
Is it suitable for me?
Organization
The organization that you are part of is a very huge part of whether the microservice architecture (MSA) is suitable for your project/product or not. Conway’s Law states that software design often reflect the organization communication structure, unsurprisingly, the inverse holds true as well.
While not a fact set in stone, there is less resistance when implementing MSA if your organization embraces the agile culture. I feel that this is mainly because MSA is an evolution of Service Oriented Architecture (SOA). Having small teams with defined roles and objectives helps with separation of concerns and works in line with the technical aspect of MSA.
Sense of ownership
This is also closely linked to the organization and culture in general. MSA is not a magic bullet that could solve all the issues with the moving target problem. The team(s) need to take ownership of the service that they are building. There is no hard and fast rule that one team should only handle one service, but the team that built the service should be the one in charge of maintaining/improving it.
There are many other factors that I won’t delve into as the books do a much better job as putting the information across. But briefly, the other factors are as level
- Location of team (across countries)
- Team size (2 pizza rule)
- Outsourcing (cultural fit)
- Competency level
So you’ve thought through all of these factors and decided, “I think my team/organization is ready for MSA, where to start?”
I can do it! But how?
Define boundaries
You would first want to find the boundaries of your services. What are boundaries? Well, in the simplest terms, it’s the part where A has to interact with B for it to execute a “different” function. What counts as different is really up for you to define. In the classic example of a shopping cart, the boundary could be the cart service and the payment service.
You would not be able to define all the boundaries correctly right from the start, and that is fine, as you could always refine and refactor your code to reflect the desired state.
One of the popular approach is to build the features that you cannot break up as a monolith, take the time to understand the context of your application, and slicing them at the seams once you’ve figured out where they belong. After a couple of months, if you’ve realised that there’s no more obvious services that could be split up, then you have reached a rather optimal state for your application, at that point in time. And I say “at that point in time” with emphasis, as with all MSA, your application and infrastructure will evolve with more traffic and features.
Another approach is to get a deep understanding of the business organization and objectives. Referencing the Conway’s Law again, you might find that splitting the services according to the organization structure might be a natural fit. There is no one-size-fits-all solution for MSA, you often have to experiment (and have an environment that encourages experimentation), in order to find the split that works well for your team.
Couple of links to get you started on identifying boundaries:
- https://codeburst.io/microservice-boundaries-five-characteristics-to-guide-your-design-89312b65cc27
- https://docs.microsoft.com/en-us/azure/architecture/microservices/model/microservice-boundaries
Log, monitor, trace
If nothing else, this is the most important point about MSA that will pretty much determine your experience in building, maintaining and extending your MSA.
Log everything, monitor your resources and implement tracing in your systems. Unsurprisingly, MSA doesn’t help you debug your application, in fact, it makes it way harder to debug. If your request to add an item to a cart failed, it’s not a single place, a single stack trace to look at; you might potentially have to look have several to dozens of services to figure out what went wrong. Don’t set yourself up for digging through hundreds of logs just to find out that the issue is someone forgot to close() a database connection.
There are many popular logging stacks out there, the most popular one is ELK (ElasticSearch, LogStash, Kibana), which I am currently using for my work, and you can find plenty of guides online on how to implement it. It gives a nice little dashboard that shows you all the info on your application. I’m not going to lie, creating a dashboard that makes sense to you is going to take a lot of work, but it is an investment I highly recommend making.

Monitoring your resources help you figure out when something weird is happening. If your service is running slowly, and your CPU is running at 100% for the past 10 minutes, it’s a sign that something is happening that uses a lot of compute resources but not the network. It helps you to narrow down the problematic area to focus on. Again, there are many tools for this, with popular ones like: Prometheus and Grafana.
However if you’re using AWS, they have an agent that does most of the heavy lifting for you, even giving you a dashboard to look at your metrics. If you’re hosting your services on the cloud, I would recommend using their native services as it reduces the amount of work you have to spend getting your services up and running.
So, what’s tracing? It’s basically a way to show you how a request flows from the start till the end. It’s like a network trace, but for applications.
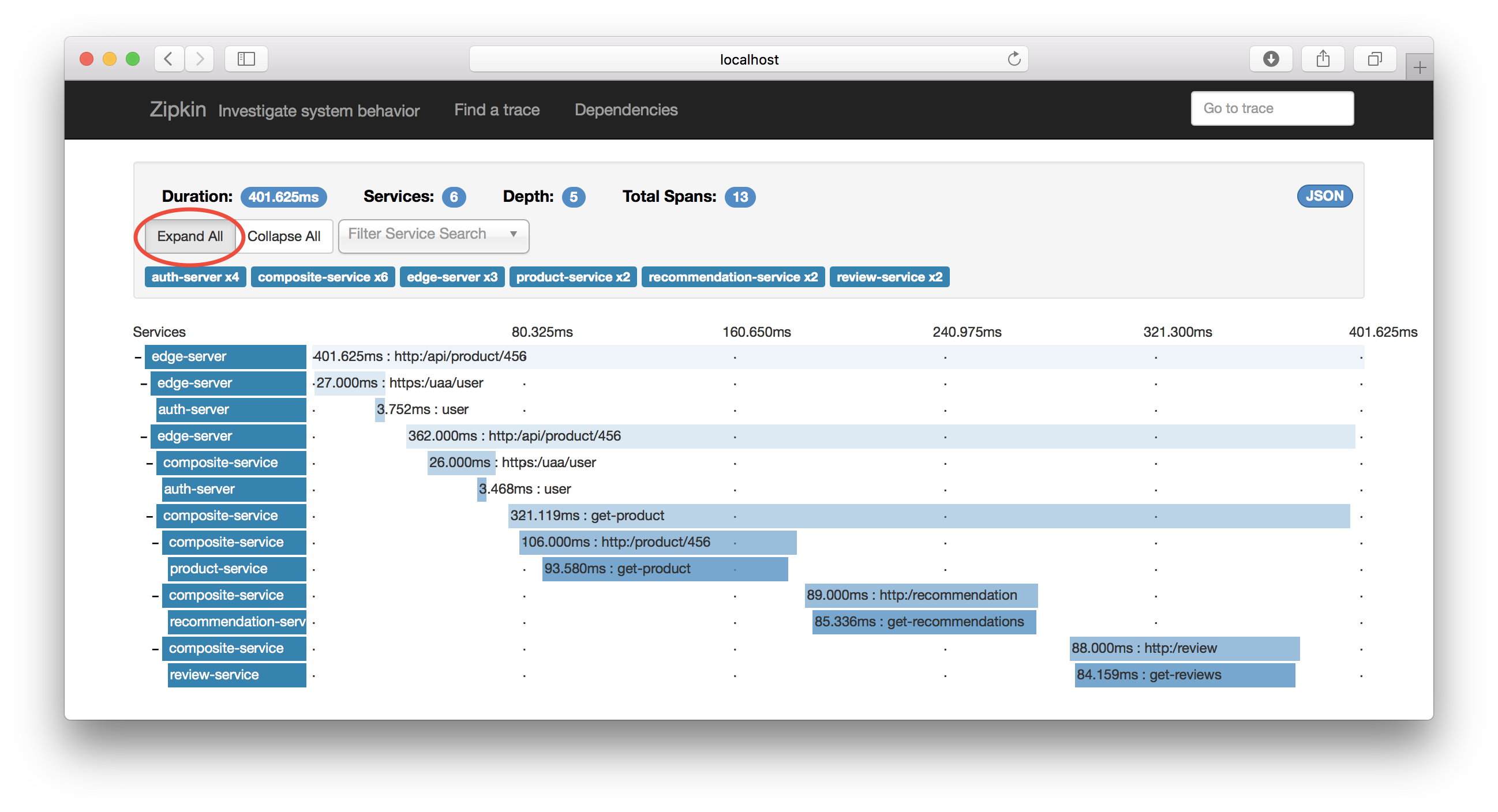
This allows you to inspect the flow of your network requests, what services take too long to process, and if the chain is broken at any point. This is an area that I am still not very familiar with yet as I am in the midst of implementing it in work. Here’s a link to a different article that might be more useful for distributed tracing.
https://opensource.com/article/18/9/distributed-tracing-microservices-world
Test resilience by breaking it
Netflix must be doing something right about testing MSA resilience because all the books and articles I’ve read always point back to their use of chaos engineering.
So, chaos engineering is a whole thing on it’s own. But here are 3 points that are the most important to me.
- Run experiments in production.
- Automate Experiments to Run Continuously
- Minimize Blast Radius
Point 1 was very hard to wrap my head around at first, like, are you crazy?! Production is supposed to be the no-touch zone for everything and you want to experiment with it?! Well turns out it makes a lot of sense. Because when things fail in your development or staging environment and you fix it, it doesn’t guarantee that the issue won’t ever happen in production because life is unpredictable. Only by running the test on production will you actually know how your system behaves with real load.
Netflix implements it to the full extent with their Simian Army, which is a set of tools that wreck chaos on their production systems, like sending a lot of junk requests, purposely slowing down network responses, and even bringing down instances randomly to test the ability of their systems to recover.
Automation is rather self explanatory, because with any bug that you can find in the system, the first question the engineer would be, “Can you replicate this?”.
Minimizing blast radius is about designing your infrastructure and software that even when a portion of it fails, the failure is contained within it’s own zone. For example, if my database fails, it shouldn’t affect the user from browsing static content. If my payment gateway is down, it shouldn’t stop the customer from being able to add their items to the shopping cart.
Well this post took way longer than expected to write, cause I wasn’t planning to go into such detail. But hopefully anyone who reads this finds it at least somewhat useful.